En esta entrada voy a describir los problemas y las estrategias que he seguido para realizar el script que extrae las palabras de la RAE.
Pasos a seguir
- Análisis de la fuente de datos
- Iterar por elementos
- Extraer información
- Descarga de la primera página
- Desarrollo de la araña
Para realizar todo esto vamos a desarrollar un script python, una vez que descarguemos la información de la web utilizaremos XPath para extraer de forma cómoda los datos.
Análisis de la fuente de datos
Iterar por elementos
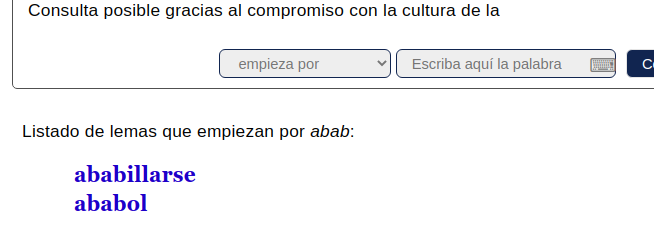
Si visitamos la web https://dle.rae.es/. Vemos que no hay forma de sacar un listado de todas las palabras que comienzan por ‘a’. Si seleccionamos del desplegable ‘Comienzan por’ y escribimos ‘a’, solo nos aparece un número limitado de palabras. Podemos ver el resultado en la siguiente url: https://dle.rae.es/a?m=31

Parece que nos saca solo 35 palabras. Si afinamos y buscamos… ‘aa’, ‘ab’, ‘ac’, etc. ¿Podremos sacar listado completos? Parece que sí aunque tenemos muchas palabras que comienzan por la letra ‘a’ así que para sacar un listado menor a 35 palabras debemos expandir las letras por las que comienzan, por ejemplo ‘abab’ https://dle.rae.es/abab?m=31
Podríamos pensar en hacer la búsqueda por fuerza bruta y hacer todas las peticiones posibles:
- aaaaa
- aaaab
- aaaac
- aaaad
- zzzzz
¿Cuántas peticiones son? Tendríamos un montón de peticiones erróneas.
El juego de caracteres en español son 27, hay que sumar la ü y las vocales acentuadas, si suponemos que necesitamos 5 caracteres para asegurarnos que la RAE no nos devuelve más de 30 resultados tenemos 33 elevado a 5 posibilidades: 39.135.393. Esto son 40 millones de peticiones.
Necesitamos una forma más elegante de hacer la navegación. Vamos a comenzar con las letras sencillas, vamos a intentar extraer las palabras que comienzan por esa letra y en el caso de tener más de 30 resultados (no tenemos el listado completo por que la RAE lo corta), vamos a expandir el conjunto de palabras a buscar pegando a esa búsqueda todas las posibilidades. El pseudocódigo quedaría así:
comienzo_a_buscar = 'a', 'á', 'b', 'c', etc...
mientras queden elemento en: comienzo_a_buscar
hacer petición a RAE
si hay más de 30 elementos
añadir a comienzo_a_buscar la combinación con alafabeto
si no
extraer información
Si vemos la ejecución de esto con la web de la RAE:
# comienzo_a_buscar al inicio
['a', 'á', 'b', 'c', 'd', 'e', 'é', 'f', 'g', 'h', 'i', 'í',
'j', 'k', 'l', 'm', 'n', 'ñ', 'o', 'ó', 'p', 'q', 'r', 's',
't', 'u', 'ú', 'ü', 'v', 'w', 'x', 'y', 'z']
# La 'a' tiene más de 30 resultados con lo que se expande
EXAPEND: a
https://dle.rae.es/aa?m=31
['aá', 'ab', 'ac', 'ad', 'ae', 'aé', 'af', 'ag', 'ah', 'ai',
'aí', 'aj', 'ak', 'al', 'am', 'an', 'añ', 'ao', 'aó', 'ap',
'aq', 'ar', 'as', 'at', 'au', 'aú', 'aü', 'av', 'aw', 'ax',
'ay', 'az', 'á', 'b', 'c', 'd', 'e', 'é', 'f', 'g', 'h',
'i', 'í', 'j', 'k', 'l', 'm', 'n', 'ñ', 'o', 'ó', 'p', 'q',
'r', 's', 't', 'u', 'ú', 'ü', 'v', 'w', 'x', 'y', 'z']
# Seguimos buscando consumiendo 'aa', 'aá' y en 'ab' tenemos más de 30... la expandimos
EXAPEND: ab
https://dle.rae.es/aba?m=31
['abá', 'abb', 'abc', 'abd', 'abe', 'abé', 'abf', 'abg',
'abh', 'abi', 'abí', 'abj', 'abk', 'abl', 'abm', 'abn',
'abñ', 'abo', 'abó', 'abp', 'abq', 'abr', 'abs', 'abt',
'abu', 'abú', 'abü', 'abv', 'abw', 'abx', 'aby', 'abz',
'ac', 'ad', 'ae', 'aé', 'af', 'ag', 'ah', 'ai', 'aí', 'aj',
'ak', 'al', 'am', 'an', 'añ', 'ao', 'aó', 'ap', 'aq', 'ar',
'as', 'at', 'au', 'aú', 'aü', 'av', 'aw', 'ax', 'ay', 'az',
'á', 'b', 'c', 'd', 'e', 'é', 'f', 'g', 'h', 'i', 'í', 'j',
'k', 'l', 'm', 'n', 'ñ', 'o', 'ó', 'p', 'q', 'r', 's', 't',
'u', 'ú', 'ü', 'v', 'w', 'x', 'y', 'z']
Ahora ya tenemos la parte de cómo navegar por toda la información.
Extraer información
Si analizamos el HTML de la web con resultados
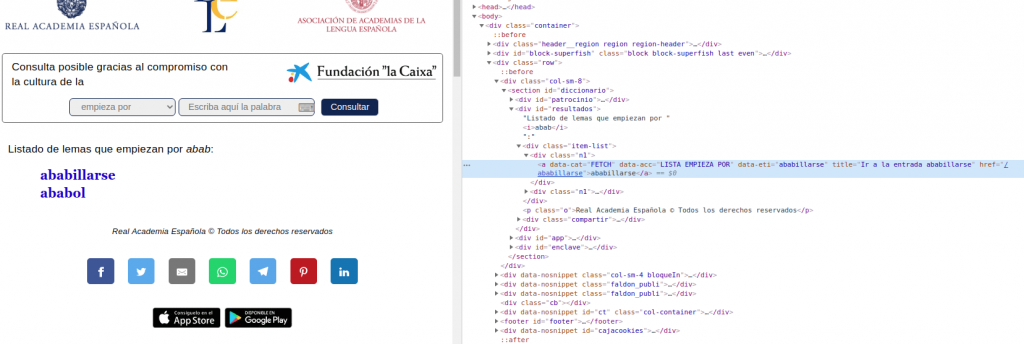
Podemos ver cómo hay un div con el identificador «resultado» y dentro de este una serie de elementos con la clase «n1». Dentro de la información de cada resultado voy a coger la información del título y voy a quitar la cadena «Ir a la entrada».
La razón para hacer esto es que no puedo coger el contenido ya que en distintos momentos la web muestra contenidos distintos:
Esos subtítulos hacen que el contenido no se pueda extraer de forma sencilla

Otro elemento a tener en cuenta es que existen palabra en femenino y masculino. Para tener todas en el listado si encontramos una comilla dentro de la palabra la combinamos

Descargando la primera página
Si desarrollamos un pequeño scrip python para hacer la descarga de la página vemos como el servidor de la REA no devuelve nada…
from urllib.request import Request, urlopen
req = Request("https://dle.rae.es/azuz?m=31")
webpage = urlopen(req)
# Da error de acceso prohibido:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.6/urllib/request.py", line 223, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib/python3.6/urllib/request.py", line 532, in open
response = meth(req, response)
File "/usr/lib/python3.6/urllib/request.py", line 642, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python3.6/urllib/request.py", line 570, in error
return self._call_chain(*args)
File "/usr/lib/python3.6/urllib/request.py", line 504, in _call_chain
result = func(*args)
File "/usr/lib/python3.6/urllib/request.py", line 650, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
¿Qué es lo que ocurre? De alguna manera el servidor de la RAE está detectando que no somos un navegador normal. Nosotros podemos imitar la petición de un navegador copiando sus cabeceras… Vamos a decir que somos un Firefox en Windows
from urllib.request import Request, urlopen
UA="Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0"
req = Request("https://dle.rae.es/azuz?m=31", headers={'User-Agent': UA)
webpage = urlopen(req)
print(webpage.readlines())
Vemos cómo ahora mismo podemos acceder a la página
Desarrollo de la araña
Aquí podéis encontrar el código completo de la araña web ya desarrollada.
Hay un elemento «raro» dentro de este código y es que cuando hacemos una búsqueda de términos relacionados con ficheros web el servidor se comporta de forma extraña. El listado de términos a evitar se ha sacado a base de ejecutar el script varias veces y detectar qué términos son. Por eso el código siguiente:
if(palabra_start_with in ['app', 'docs', 'js']):
continue
El script entero es el siguiente
#!/usr/bin/env python3
# Desarrollado por Jorge Dueñas Lerín
from urllib.parse import quote
from urllib.request import Request, urlopen
from lxml import etree
import time
UA="Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0"
url="https://dle.rae.es/{}?m=31"
to_remove_from_title='Ir a la entrada '
"""
Usamos title por que el contenido en determinadas situaciones cambia:
<a data-cat="FETCH" data-acc="LISTA EMPIEZA POR" data-eti="abollado" title="Ir a la entrada abollado, abollada" href="/abollado">abollado<sup>1</sup>, da</a>
"""
skip = len(to_remove_from_title)
letras = ['a', 'á', 'b', 'c', 'd', 'e', 'é', 'f', 'g', 'h', 'i', 'í', 'j', 'k', 'l', 'm',
'n', 'ñ', 'o', 'ó', 'p', 'q', 'r', 's', 't', 'u', 'ú', 'ü', 'v', 'w', 'x', 'y', 'z']
#Para comprobar la necesidad de title
#letras = ['abonado']
start_withs = letras.copy()
ftodas = open("palabras_todas.txt", "w")
while len(start_withs) != 0:
palabra_start_with = start_withs.pop(0)
if(palabra_start_with in ['app', 'docs', 'js']):
continue
req = Request(url.format(quote(palabra_start_with)), headers={'User-Agent': UA})
print (req.full_url)
print (start_withs)
webpage = urlopen(req)
htmlparser = etree.HTMLParser()
tree = etree.parse(webpage, htmlparser)
res = tree.xpath('//*[@id="resultados"]/*/div[@class="n1"]/a/@title')
# Se repiten palabras. Cuando por ejemplo aba tiene más de 30 y se exapande
# abaa, abab, etc... las primeras palabras no aparecen: aba
for pal in res:
pal_clean = pal[skip:]
pal_clean = pal_clean.split(", ")
for p in pal_clean:
print(p)
ftodas.write(p+'\n')
if(len(res)>30):
print("!" * 80)
print("EXAPEND: " + palabra_start_with)
expand = [palabra_start_with + l for l in letras]
start_withs = expand + start_withs
ftodas.close()
exit()
Conclusión
Hemos visto cómo podemos programar arañas que imitan un navegador y cómo podemos navegar por la web. Ya casi tenemos todo listo para hacer google2 🙂
Gran trabajo! Gracias por compartirlo!
Doctor:
deberia de dejar el archivo de texto generado por aqui.
para que no tengamos que consultar masivamente en la RAE todos los interesados.
Sin embargo, le felicito por su codigo.
Tengo todo subido en https://github.com/JorgeDuenasLerin/diccionario-espanol-txt
Gracias por tu comentario.
Lo corri por 5 min y llego hasta la palabra administratorio… esto es masivo!
Gran trabajo pero una duda me llama la atención.
¿Sería posible no incluir las declinaciones verbales en el listado sino simplemente los infinitivos?
Buenas,
Excelente script, me ha salvado el problema de las palabras para crear un crucigrama.
Si alguien necesita sacar las definiciones, adjunto unas lineas para obtenerlas sin ejemplos ni exponentes (usados como enlaces a otras palabras)
# Sin ejemplos
for bad in tree.xpath(‘//*[@id=»resultados»]/*/p[@class=»j»]//span[@class=»h»]’): bad.getparent().remove(bad)
#Sin exponentes
for bad in tree.xpath(‘//*[@id=»resultados»]/*/p[@class=»j»]/*/sup’): bad.getparent().remove(bad)
#Lista de definiciones de la palabra en un string
defins = ».join(tree.xpath((‘//*[@id=»resultados»]/*/p[@class=»j»]//text()’)))
# Separar cada definicion por la numerologia inicial y eliminar esta
for defi in re.split(r’\d+\.\s’, defins)[1:]: definicion = «».join(defi).strip()
Hola!
Me interesa saber si se puede extraer cada palabra con al menos un significado… ¿lo has intentado? Estoy pensando en hacer una sopa de letras en python como proyecto de aprendizaje y seria genial nutrirse de un diccionario.
Lo tengo en tareas pendientes… a ver si saco un hueco y lo hago en los próximos días.
Muchas gracias por tu estupendo trabajo, me ha ayudado para agregar palabras al listado que tiene mi corrector ortográfico para médicos y otros listados.
Excelente trabajo. Gracias por código súper detallado. Aprendí mucho. Saludos,